





Wie man KI-Wissensdatenbanken aufsetzt

Du kennst das Problem aus deinem Arbeitsalltag. Ein Kollege braucht dringend eine technische Spezifikation. Du weisst genau, dass die Information existiert. Aber sie ist irgendwo in einem PDF, im Intranet oder in einer alten Präsentation vergraben. Die Suche kostet dich oft 20 Minuten oder mehr. Diese Zeit fehlt dir für deine eigentliche Arbeit.
Wissensdatenbanken sind heute entscheidend
Es geht nicht nur darum, Zeit zu sparen. Es geht darum, wertvolles Know-how im Unternehmen zu sichern. So bleibt das Wissen im Haus, auch wenn Mitarbeitende gehen.
Gleichzeitig ist eine saubere Wissensbasis das Fundament für viele KI-Projekte. Wer seine Daten heute im Griff hat, ermöglicht Anwendungen mit echtem Mehrwert. Ohne diese Basis bleibt Künstliche Intelligenz nur eine nette Spielerei ohne Tiefgang.
Viele scheitern bei der Umsetzung von RAG-Systemen. Der häufigste Fehler ist die Annahme, dass man einfach Dokumente ungefiltert in einen Topf werfen kann. Man hofft, dass die KI den Rest erledigt. Das führt zu ungenauen Antworten oder erfundenen Fakten. Wenn die KI den Unterschied zwischen einer Preistabelle und einem Fliesstext nicht versteht, ist das System wertlos.
Wie wir vorgehen bei der Erstellung
Wir bauen zuerst ein sauberes Fundament. Im ersten Schritt analysieren wir die Rohdaten gründlich. Oftmals muss man hier noch Inhalte säubern, beispielsweise eingescannte PDFs in Text umwandeln oder Inhalte von Grafiken richtig interpretieren. Wir trennen anschliessend strukturierte Informationen wie Tabellen konsequent von unstrukturierten Texten.
Dann segmentieren wir die Inhalte in logische Einheiten, sogenannte Chunks. Dabei achten wir darauf, dass der Kontext jeder Information erhalten bleibt. Nur so kann die KI später die richtigen Zusammenhänge herstellen und präzise antworten.
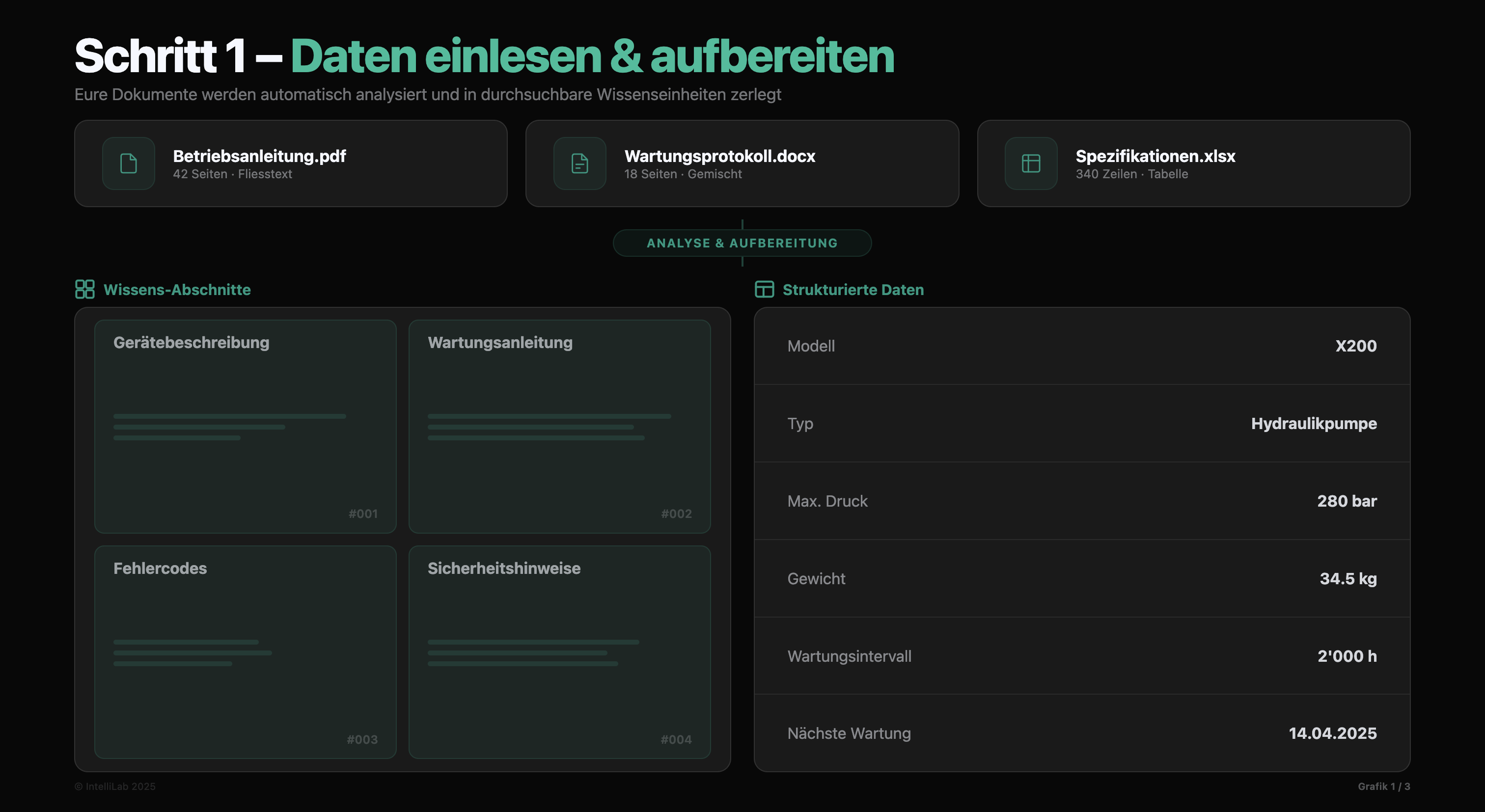
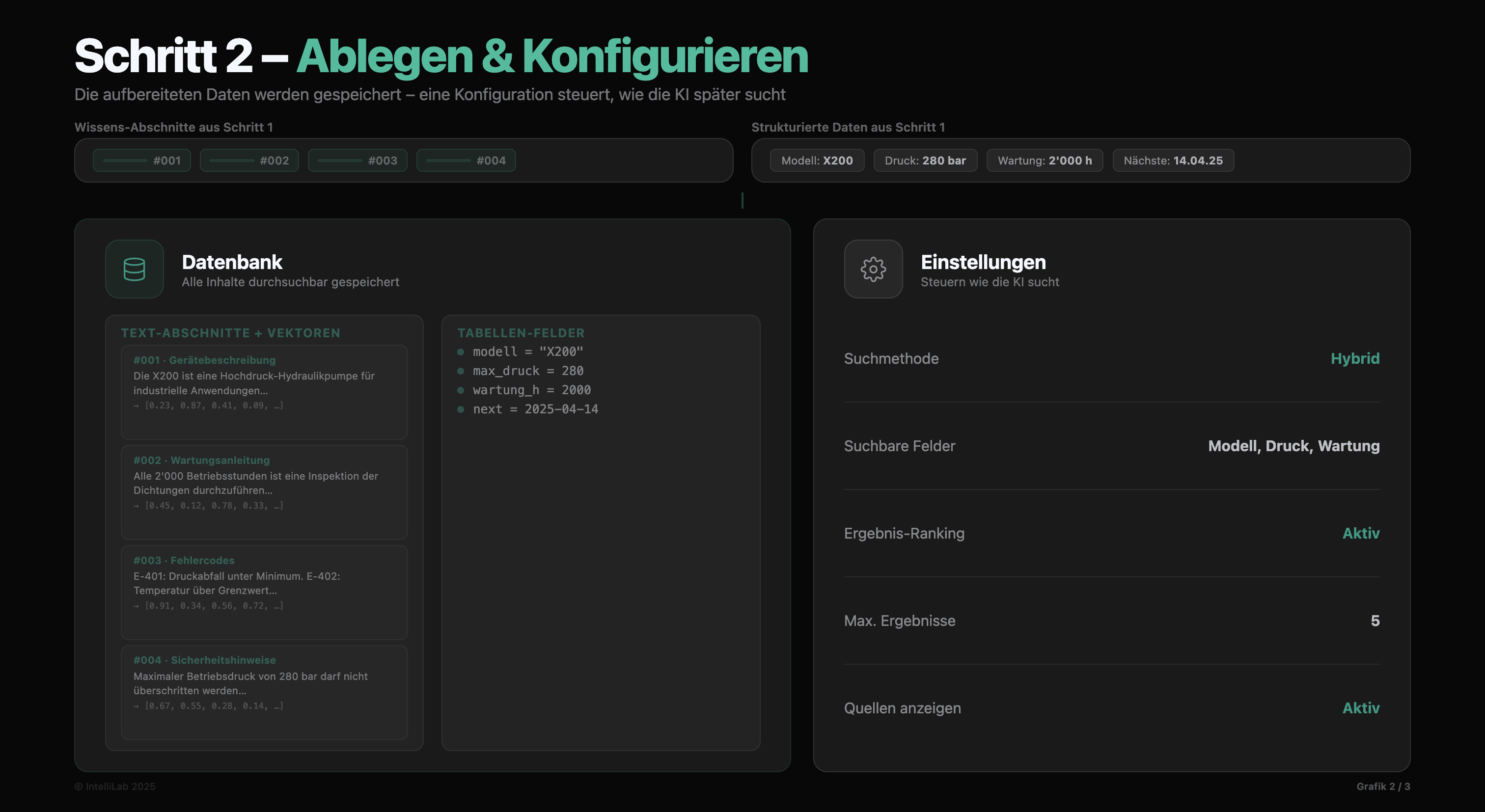
Danach geht es an die Speicherung. Wir legen die Daten nicht einfach unsortiert ab. In Grafik 2 siehst du, wie wir die Informationen in spezialisierten Datenbanken strukturieren. Entscheidend ist hier die Configuration Layer.
Diese Schicht ist das Regelwerk deiner Wissensdatenbank. Hier definieren wir genau, wie die KI mit den abgelegten Daten umgehen muss. Die Configuration Layer legt fest, wo welche Informationen liegen und welche Prioritäten bei der Verarbeitung gelten. Das sorgt für maximale Verlässlichkeit und Geschwindigkeit bei jeder Abfrage.
Der eigentliche Nutzwert entsteht im Dialog zwischen Mensch und Maschine. Unser System nutzt eine hybride Suche. Es findet die relevanten Informationen aus tausenden von Seiten in Millisekunden.
Wie dieser Prozess genau abläuft, siehst du in dieser Grafik. Ein Nutzer stellt eine Frage in natürlicher Sprache. Das System löst daraufhin einen Retrieval-Prozess aus. Es sucht in den Datenbanken nach den exakt passenden Inhalten für dieses spezifische Problem.
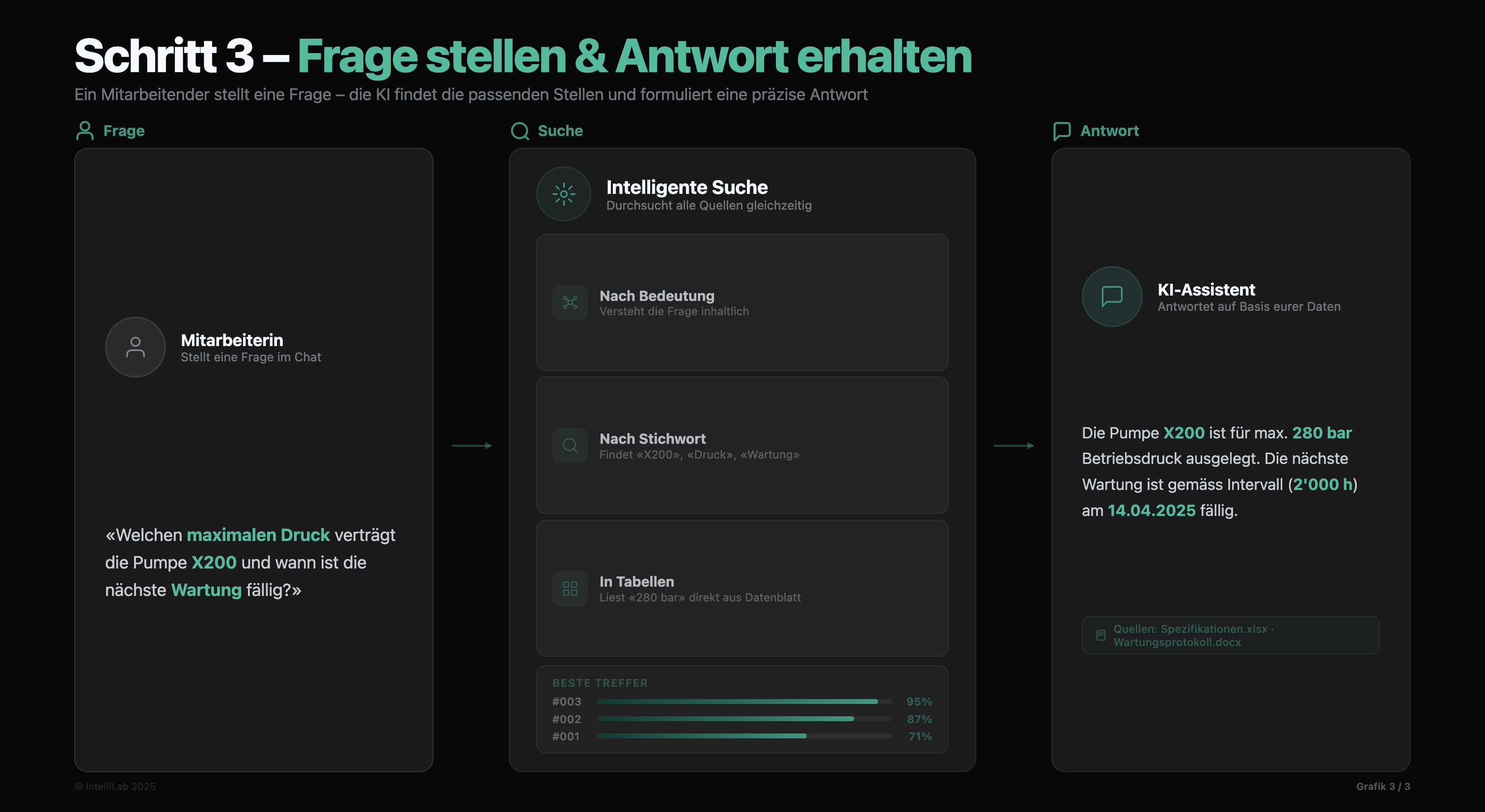
Diese internen Daten dienen als exklusive Grundlage für die Antwort der KI. Das Ergebnis sind präzise Fakten statt Halluzinationen. Besonders wichtig für die Transparenz: Jede Antwort wird direkt mit der entsprechenden internen Quelle belegt. Du kannst per Klick prüfen, aus welchem Dokument die Information stammt.
Deine bestehenden Zugriffsrechte bleiben dabei voll erhalten. Die Configuration Layer stellt sicher, dass jeder Mitarbeitende nur die Informationen erhält, für die er eine Berechtigung hat. Sicherheit und Datenschutz sind fest im System verbaut.
So verwandelst du statische Dokumente in aktives, jederzeit abrufbares Wissen. Du schaffst die Basis für deine digitale Zukunft und machst dein Unternehmen effizienter.
Interesse an einer eigenen KI-Wissensdatenbank? Lass uns gerne darüber sprechen, wie man dein Unternehmenswissen verfügbarer machen kann.
Das könnte dich auch interessieren
Entdecke die faszinierende Welt der künstlichen Intelligenz und tauche ein in unzählige weitere spannende Blogartikel, die dir ein tieferes Verständnis über dieses zukunftsweisende Thema vermitteln!

Die Mitarbeiter der Zukunft (Webinar AI-Agents)
In diesem Beitrag zeigen wir dir, wie wir KI-Mitarbeiter oder sogar ganze Abteilungen bauen.

Datenschutz bei der Nutzung von Webservices
In diesem Artikel erklären wir dir, wie Webservices deine Daten nutzen und wie ShieldGPT Unternehmen hilft, ihre Daten sicher und effizient zu verwalten.
.avif)
.avif)
Wie wir KI-Usecases sinnvoll priorisieren
Viele Unternehmen stolpern beim Start mit KI über dieselbe Frage: Welche Use Cases lohnen sich wirklich? Wir zeigen Formeln, die helfen, klar zu priorisieren.
Bereit, KI richtig anzugehen?
Lass uns im Gespräch herausfinden, wo bei dir der grösste Hebel liegt. Wir zeigen dir, wie du KI als echten Wettbewerbsvorteil nutzt.
